Neden Tuba Büyüküstün olmak kolay da, Kıvanç Tatlıtuğ olmak zordur?

Şu Corona günlerinde Netflix'teki İstanbul'un fethini anlatan Rising Ottomans'ı izlediniz mi? Bizimle alakalı konular o yüzden izlemesi keyifli. Celal Hocamız arada "huge" falan diyor, ama Tuba Büyüküstün’ü görünce "aga ne yaptın sen!?" diyorsunuz.
Bir oyunculuk ki nereden tutsan elde kalıyor. Peki neden bu güzel kadınımız oyunculukta bu kadar kötü? Hayır, bir de bu Tuba'ya özel bir durum da değil. Nerede güzel ya da yakışıklı oyuncu var bir o kadar yeteneksizler. Yetenek ile güzellik arasında acaba ters korelasyon mu var?
Konuyu incelemek için kendi verimizi oluşturalım. Bunun için iki adet nedensellik ilişkisi belirleyelim. Aynı IQ gibi iki puan tanımlayalım. Yetenek puanı YQ, güzellik puanı GQ olsun. Yetenekli olmak sizi ünlü yapsın (Yüksek YQ -> Ü) ya da güzel olmak sizi ünlü yapsın (Yüksek GQ -> Ü).
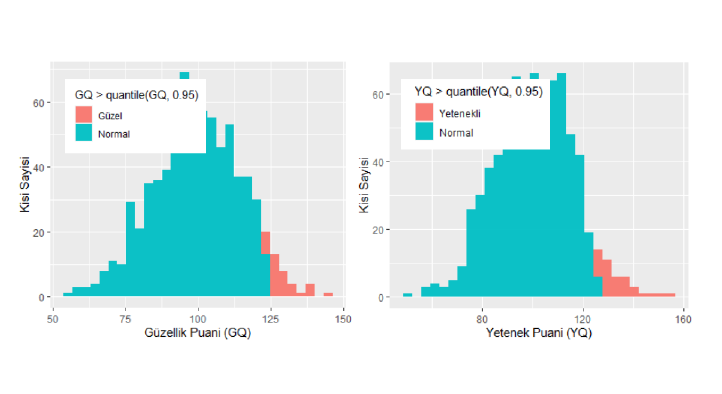
Hatta bu konuda çok net olalım. En güzel %5’lik kesim ve en yetenekli %5’lik kesim ünlü olsun. Yetenek ve güzellik puanlarının dağılımlarını IQ gibi farz edelim. Ortalamaları 100, standart sapmaları da 15 olsun. Şimdi bu kurallara uygun 750 kişiden oluşan bir grup yaratalım ve hepsine GQ ve YQ puanları dağıtalım.
yq <- rnorm(750, 100, 15)
gq <- rnorm(750, 100, 15)
data <- data.frame(YQ=yq, GQ=gq)
data$U <- factor(data$YQ >= quantile(yq, 0.95) | data$GQ >= quantile(gq, 0.95), c(TRUE, FALSE), c("ÜNLÜ", "NORMAL"))
data$G <- factor(gq > quantile(gq, 0.95), c(TRUE, FALSE), c("Güzel", "Normal"))
data$Y <- factor(yq > quantile(yq, 0.95), c(TRUE, FALSE), c("Yetenekli", "Normal"))
ggplot(data) + aes(x=GQ, fill=G) + geom_histogram(alpha=0.95) + xlab('Güzellik Puanı (GQ)') + ylab('Kişi Sayısı') + labs(fill = "GQ > quantile(GQ, 0.95)")
ggplot(data) + aes(x=YQ, fill=Y) + geom_histogram(alpha=0.95) + xlab('Yetenek Puanı (YQ)') + ylab('Kişi Sayısı') + labs(fill = "YQ > quantile(YQ, 0.95)")
Yukarıda iki farklı dağılımı gösterdim. 750 kişilik grubumuzda yeteneklerin ve güzelliğin dağılımı bu. Tabi güzellik insandan insana değişir, ne bu puanlama diyeniniz olacaktır. Bu güzel bir soru. Peki yetenek tanımı da kişiden kişiye değişmez mi? Zeka tanımı da kişiden kişiye değişmez mi? IQ nedir o zaman? Şimdilik tanım konusu bir kenara bırakıp bir mühendis edasıyla yararcı olup lütfen şu puanlandırmaları doğru kabul edelim.
Ne demiştik en yetenekli ve en güzel %5. Ne yapıyor bu? Oluşturduğum sentetik veriye göre yetenek için 125 puandan yüksek kişiler, güzellik için ise 124 puandan yüksek kişiler. Grafiklerde de onları ayrı renklendirdim. Hadi şimdi bu iki veriyi aynı grafik üzerinde çizelim.
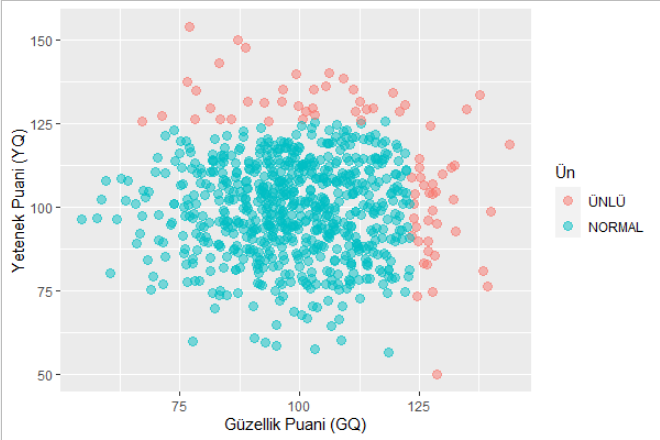
ggplot(data) + aes(x=GQ, y=YQ, color=U) + ylab('Yetenek Puanı (YQ)') + xlab('Güzellik Puanı (GQ)') + geom_point(alpha=0.5, size=3) + labs(color = "Ün")Üstü ve sağ tarafı kare şeklinde kesilmiş mavi ünsüzler ve belli puanların üstünde olan ünlüler burada. Şu grafikten ünsüzleri atalım, bizim onlarla işimiz yok. Bizim derdimiz neden güzel ünlüler yeteneksiz onu bulmak.
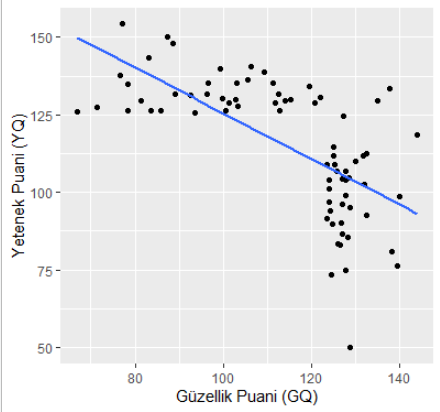
filtered_data <- data[data$U == "ÜNLÜ",]
model <- lm(YQ ~ GQ, filtered_data)
summary(model)
ggplot(filtered_data, aes(x=GQ, y=YQ)) + ylab('Yetenek Puanı (YQ)') + xlab('Güzellik Puanı (GQ)') +
geom_point()+
geom_smooth(method=lm, se = FALSE)Ahanda aynen dediğimiz gibi, güzel ünlüler yeteneksiz. Ben veriyi tanımlarken güzellik ve yetenek arası bir korelasyon söylemedim. Bunları tamamen bağımsız iki normal dağılım olarak tanımladım. Üstelik kodu da yukarıda. Aralarında nedensellik de yok, yani güzelseniz yeteneksiz olursunuz falan demedim. Ama şu an yetenek ve güzellik arasında ters bir korelasyon var. Üstelik bu korelasyon konusunda %99.9999 oranında eminiz ki şansa da oluşmamış.
Bunun nedeni bayesian networkler de collider dediğimiz olay (Yüksek YQ -> Ünlü <- Yüksek GQ). Yani oyunculuk konusunda da güzellik konusunda da iyi olan Kıvanç Tatlıtuğ bir istisna. Gerçi onun da oyunculuğunu ya da güzelliğini beğenmeyeniniz vardır.
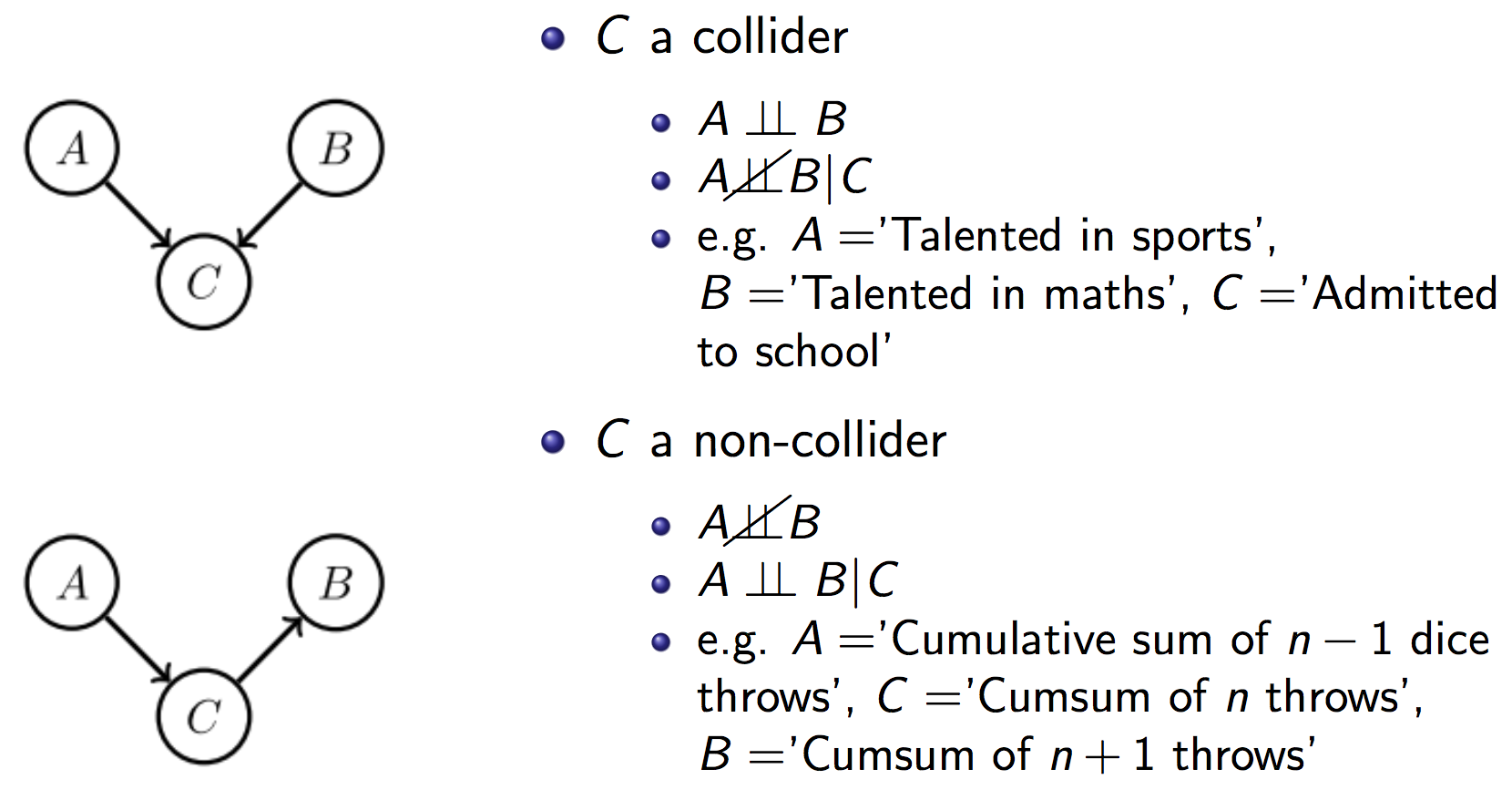
Yani eğer biri ünlüyse ve güzelse muhtemelen yetenekli değildir. Çünkü zaten ünlü olmak için bir nedeni var diğer konuda dağılımı tüm kişilerle aynı olacak. Yani güzel bir ünlüden yetenek beklentimiz 100 YQ tıpkı tüm popülasyon gibi. Ama YQ beklentimiz ünlüler arasında yüksek olduğu için güzelimiz görece olarak yeteneksiz olma ihtimali yüksek. Bu normalde bağımsız olması gereken birden fazla nedenli her yerde geçerli. Güzellik ve yetenek normalde bağımsızlar ama yeni bir bilgi olan ünlülük bu iki random variable bağımlı hale getiriyor.
Örneğin birini sevmeniz için bir neden yeterliyse; sevdiğiniz kişi güzelse zeki değildir ya da zekiyse güzel değildir. Ya da şu sıralar ateşiniz varsa ve nezleyseniz muhtemelen COVID-19 değilsinizdir, COVID-19'sanız muhtemelen nezle değilsinizdir. İstatistik çok güzel bir şey. Her konu hakkında arkası doldurulabilir bir sözümüz var. Şimdi de eleştirmen olduk.
Bu da Causality serimin Bayesian Networklere giriş yaptığım ikinci yazısı oldu, bir sorun çıkmaz ise 5-6 yazılık bir seri bizleri bekliyor. Burada RCT (Randomized Controlled Trial) yapmadan nasıl causality çalışılır o konulara gireceğiz, görüşmek üzere, sağlıklı kalın.