Machine Learning in Production Series 1 - Scoping & Data


Machine Learning(ML) is a tedious process with different challenges. Writing a quick model might be easy however one should spend much more time to productionize the model. There are many considerations such as balancing the load, dealing with huge data, monitoring the output to make sure of continuos quality.
In my journey to learn more about ML on production, I am taking Machine Learning Engineering for Production (MLOps) Specialization from Deeplearning.ai . In this blog post series, I will try to summarize my learnings as a way to review myself. Almost all of the visualizations I will use in this post are sourced by the presentations in the specialization.
So I will just dive. Thanks for reading in advance.
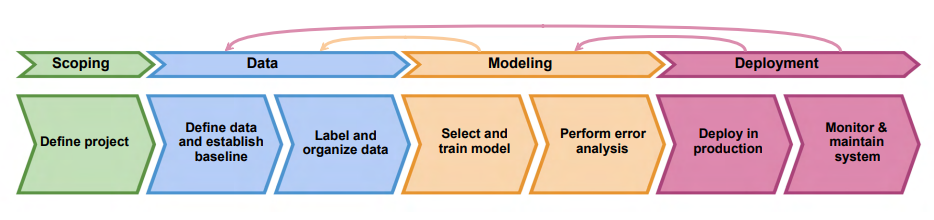
Steps of an ML Project
There are 4 natural steps in ML project life cycle. Those are scoping, data, modeling and deployment. In this first post of the series, I will be only focusing on first 2 steps.
SCOPING
Scoping is all about knowing which battles you want to fight. We cannot solve all problems not only because of time / capacity but because some problems are just not worth the effort.
Some of the questions to ask for picking the right battle are :
- What are the projects which would create highest impact?
- What are the metrics of success?
- Do we have the resources (data, time, people)?
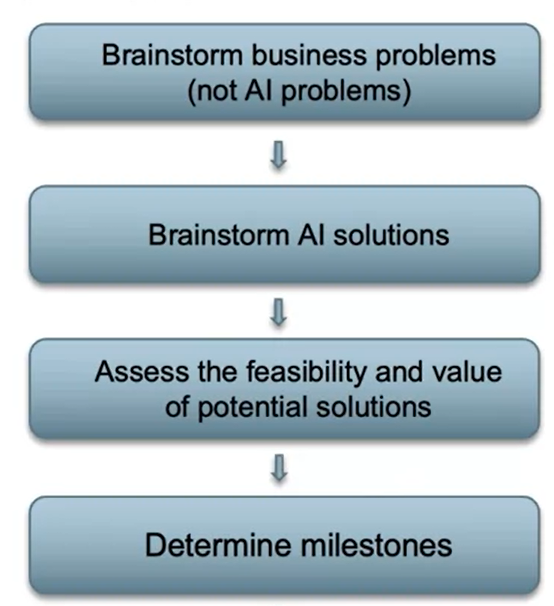
At this step it is important to sit together with business and learn their priorities. The priority can for example be increasing profit via changing price or decreasing cost by reducing labor on a manual task. Only after learning about the priorities it is possible to brainstorm about AI solutions. After some potential solution matures, it is important to think about feasibility of the project as well as determining some milestones.
Feasibility
I would like to open a parenthesis here because knowing if a solution is feasible or not can save immense time. For tasks including unstructured data (such as sound or visuals), Andrew Ng suggest using Human Level Performance (HLP) as the best possible level. So for this cases the question is:
Can a human, given the same data, perform the task?
For structured data, such as tabular data, the question is a bit less intuitive. Here we should ask if the data has any information which might be used for inferring the output.
Do we have features that are predictive?
DATA
This the hardest step and almost always the bottle neck. You know how they say "Data is the new petroleum", this is because a mediocre algorithm using great data performs much better than a great algorithm using poor data. It is possible look for good models in literature or via tutorials however you can't easily find data. Because of this reason it is much more efficient to do data-centric AI compared to model-centric AI especially in industry.
Model Centric AI: Optimizing/iterating model while keeping the data fixed
Data Centric AI: Prioritizing the quality of the data compared to algorithm
Data can be increase in 3 possible way.
- Increasing the amount by labeling new instances (Data Labeling)
- Increasing the amount by generating realistic instances (Data Augmentation)
- Increasing the dimension by creating new features.
Data Labeling
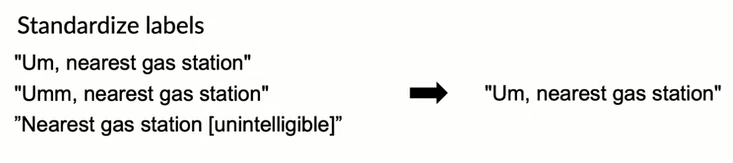
Unlike Kaggle type ML problems, in production we might actually need to create our own dataset. In those cases one issue is to come up with clear labeling rules. For example for an NLP data building task, we should decide on how to deal with filler words such as "umm" .
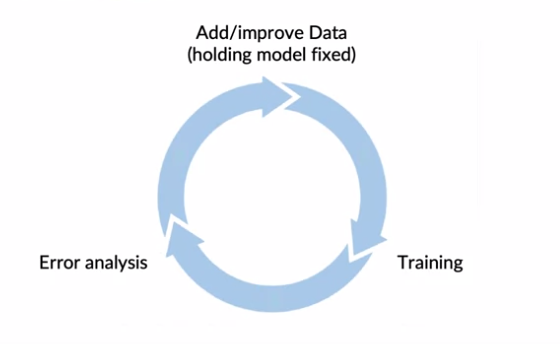
Data labeling could be expensive and time consuming. Thus if possible a good way to do that is to put this step in the development cycle i.e developing model -> Doing Error Analysis -> Labeling data related to errors.
Data Augmentation
Data augmentation is the method of generating artificial data for using in model training. The important key point here is creating realistic data points that the algorithm does poorly on, but humans(or other baseline) do well.
This process of data augmenting from a data centric development angle can be represented as an iteration loop.
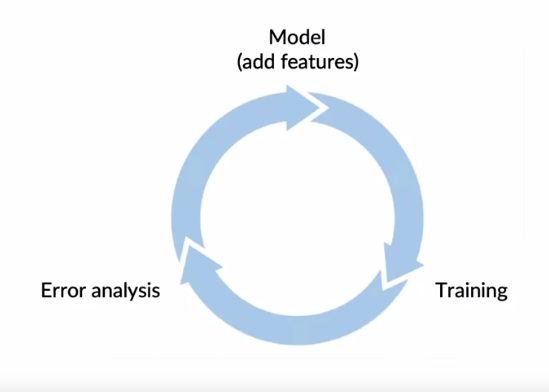
Adding Features
Sometimes it is just hard to generate data. For example, if you are developing a recommendation system it might not be possible to generate realistic data. In those cases, it is helpful to think in terms of possible features to add.
For example assume that you have built a recommendation system. However after doing an error analysis you have realized that the system performs poorly because it is sometimes recommending non-vegetarian food to vegetarian people. This type of issue can be fixed by adding features flagging if the restaurant to be recommended have vegetarian option and if the person is vegetarian. This type of feature engineering might be especially relevant for structured data.
Data Lineage & Data Provenance
As we have already discussed, data is the core part of model. We cannot replicate a model without using exactly same data for retraining. Thus data versioning, knowing how the data was sourced is an important point to take into consideration. In this context there are two commonly used terms: data provenance and data lineage. Data provenance refers to where the data came from / how it was obtained. Data lineage, on the other hand, refers to the sequence of steps needed to get to the end of the pipeline.
In this first post of the series, we have focused on the first 2 steps of the ML project life cycle. Even though these steps are not the ones where we see the action or any final product, these are fundemental steps which have tremendous importance. Having a solid understanding of those can save incredible time.
In the next writing of the Machine Learning in Production Series, we will be focusing on modeling and monitoring concepts.